Ubuntu配置hadoop(基于Docker)
大数据挖掘需要搭建Linux虚拟机上的hadoop集群
踩过的坑都在这里了
前言
在大数据挖掘和Linux这两门课都需要搭建Linux环境,老师的推荐都是VMware等虚拟机,我觉得用Docker容器更加方便一些,于是就找教程用Docker创建Ubuntu容器,但是踩了很多坑,还好都解决了,现在记录一下。
一、启动Docker容器
首先pull一个Ubuntu镜像
1 | docker pull ubuntu |
注意这边直接pull ubuntu的话会直接下载最新版本,可以通过ubuntu:18.04来下载指定版本
接着通过镜像运行一个容器
1 | docker run -dit --name=main -p 9870:9870 -p 8088:8088 ubuntu |
注意这里要使用-p指令开放9870和8088两个端口,之后会用到
使用docker exec命令进入容器
1 | docker exec -it main /bin/bash |

二、安装jdk
在Ubuntu中用压缩包安装jdk较为麻烦,需要配置系统环境变量和配置文件,一步出错可能无法使用。所以本文在Ubuntu中使用命令安装jdk。其他方法安装jdk也可。
打开终端
执行以下命令:
1 | sudo apt-get install openjdk-8-jdk |
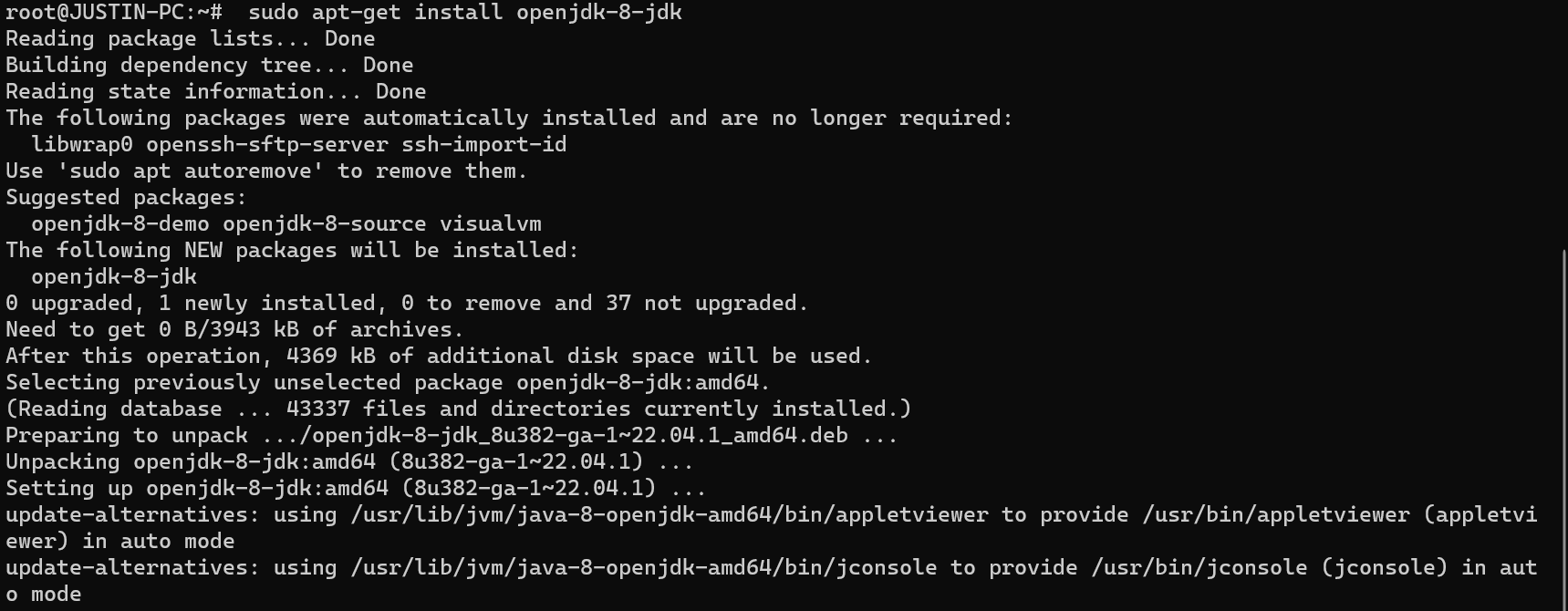
如果报错bash: sudo: command not found的话,先执行下面两个命令
1 | apt-get update # 更新apt-get |
安装完成后查看Java是否安装成功
1 | java -version |
如下图所示则安装成功:

如果需要卸载jdk则使用以下命令:
1 | sudo apt remove openjdk* |
三、配置环境文件
打开环境文件
1 | sudo vim ~/.bashrc |
如果没有vim编辑器则需要下载:
1 | sudo apt-get install vim |
或使用gedit编辑器也行
加入语句
文件顶部加入以下语句并保存:
1 | export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 #目录要换成自己jdk所在目录 |
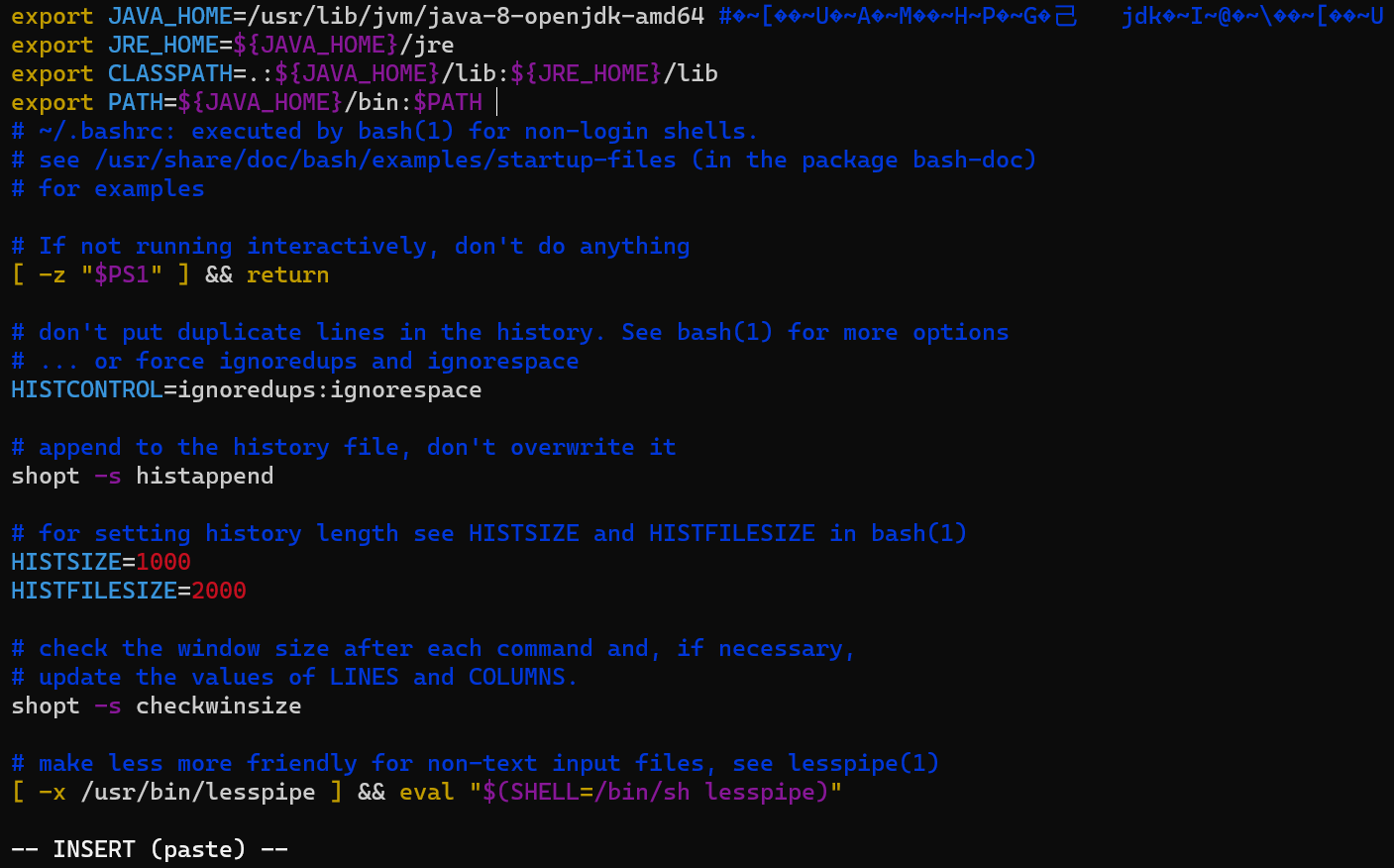
使环境生效
1 | source ~/.bashrc |
使用 echo $JAVA_HOME 显示JAVA_HOME即为成功

四、安装ssh免密码登录
1 | sudo apt-get install ssh openssh-server |
安装完毕后先cd到~
1 | cd ~ |
再创建.ssh文件夹
1 | mkdir .ssh |
再cd到.ssh中
1 | cd .ssh |
生成密钥
1 | ssh-keygen -t rsa |
按三次回车

将秘钥加入到授权中
1 | cat id_rsa.pub >> authorized_keys |
再验证ssh localhost 如下图,不用密码登录即为成功
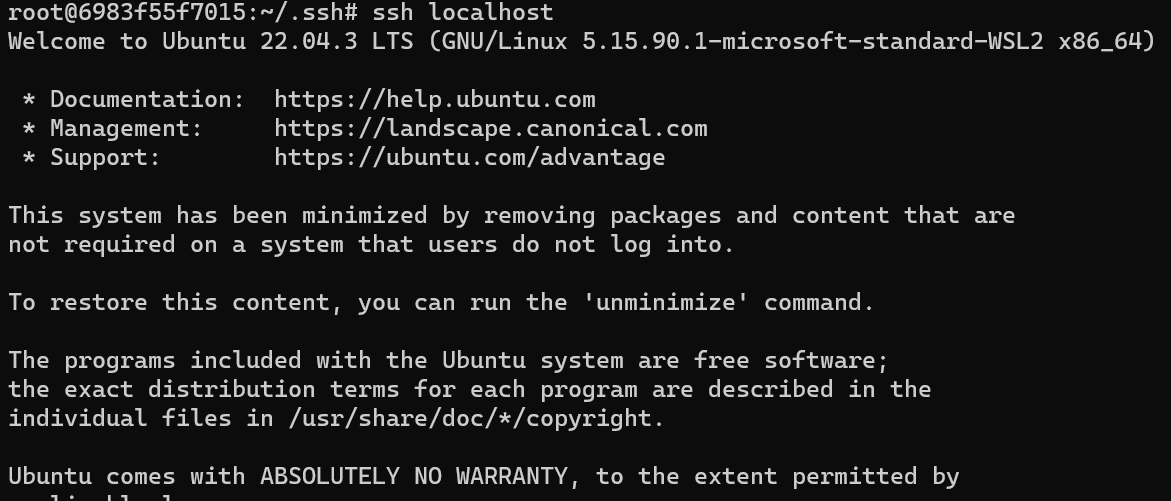
如果发生以下报错,那就看这个博客的解决方案 这里

五、安装Hadoop
1)安装hadoop并解压
先cd到/usr/local
1 | cd /usr/local |
镜像下载链接https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.1/
1 | wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz |
然后解压后进入文件夹
1 | tar -zxvf hadoop-3.3.1.tar.gz |
2)配置相关文件
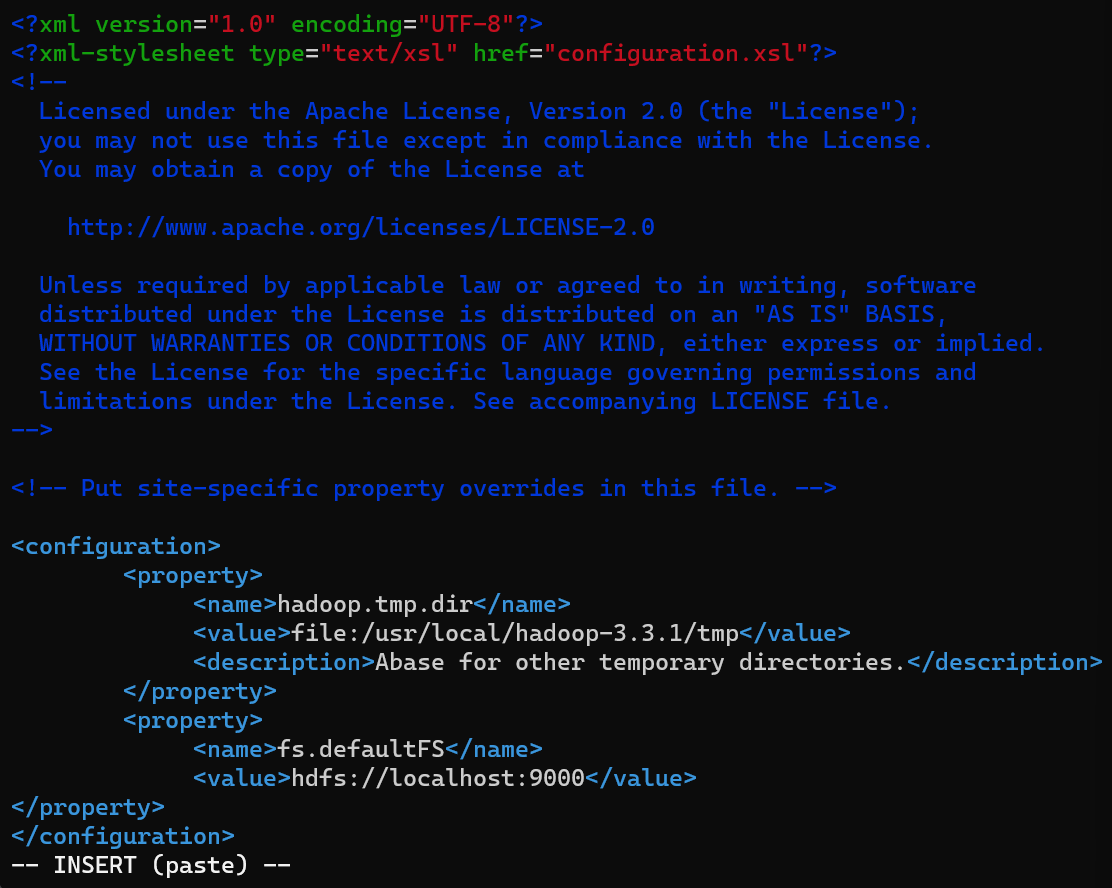
core-site.xml
打开/etc/hadoop中的core-site.xml 文件,加入如下语句并保存
注意在在
configuration标签中加入
1 | <property> |
hdfs-site.xml
和上面一样,打开/etc中的hdfs-site.xml 文件,加入如下语句并保存
1 | <property> |
hadoop-env.sh
查看你的 jdk安装目录
1 | echo $JAVA_HOME |
打开 hadoop-env.sh 文件配置如下并保存:
1 | export JAVA_HOME="/usr/lib/jvm/java-8-openjdk-amd64" # 根据自己的路径写 |
六、运行Hadoop
1)首先初始化HDFS系统
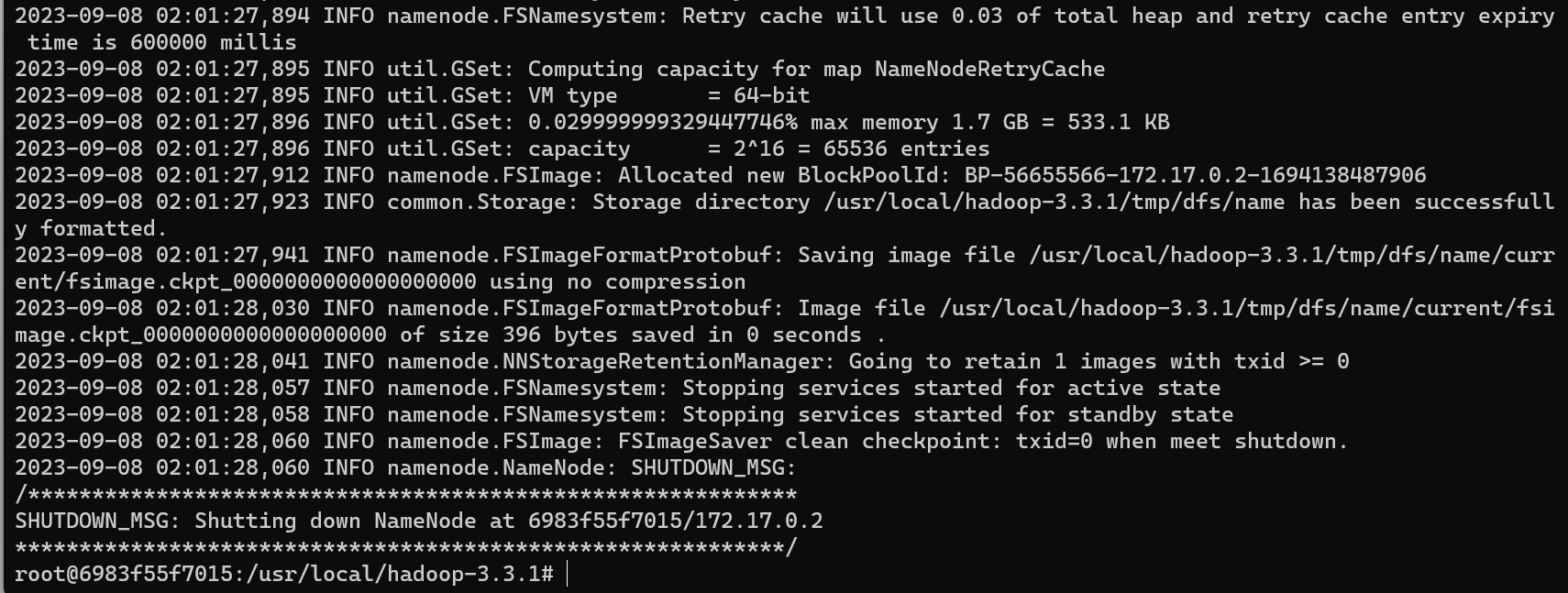
在hadop3.3.0目录下使用如下命令进行初始化:
1 | bin/hdfs namenode -format |
成功后如下图:
2)开启NameNode和DataNode守护进程
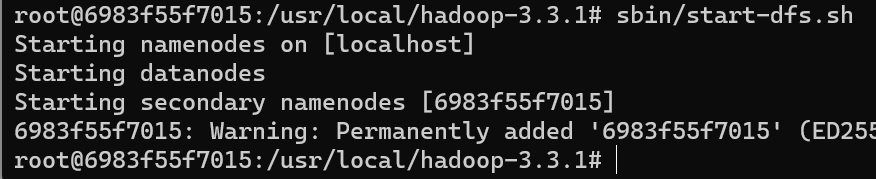
继续运行如下命令开启Hadoop:
1 | sbin/start-dfs.sh |
成功后如下图:
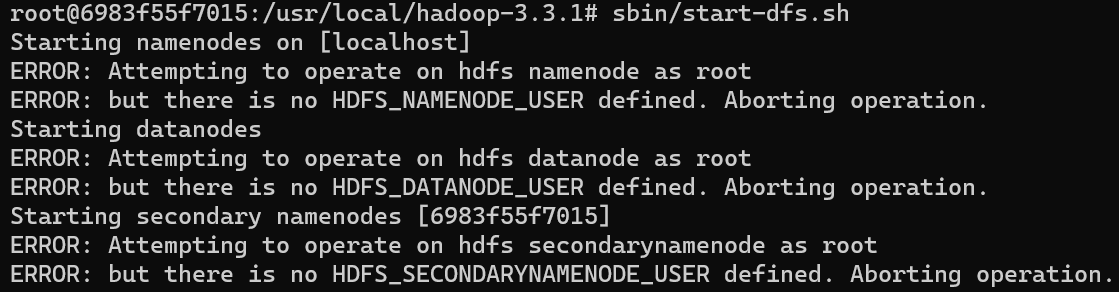
如果出现以下报错,请查看这个博客 这里
3)查看jps进程信息
1 | jps |
如下图即为成功: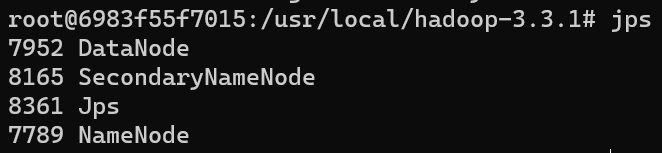
关闭hadoop使用命令 sbin/stop-dfs.sh
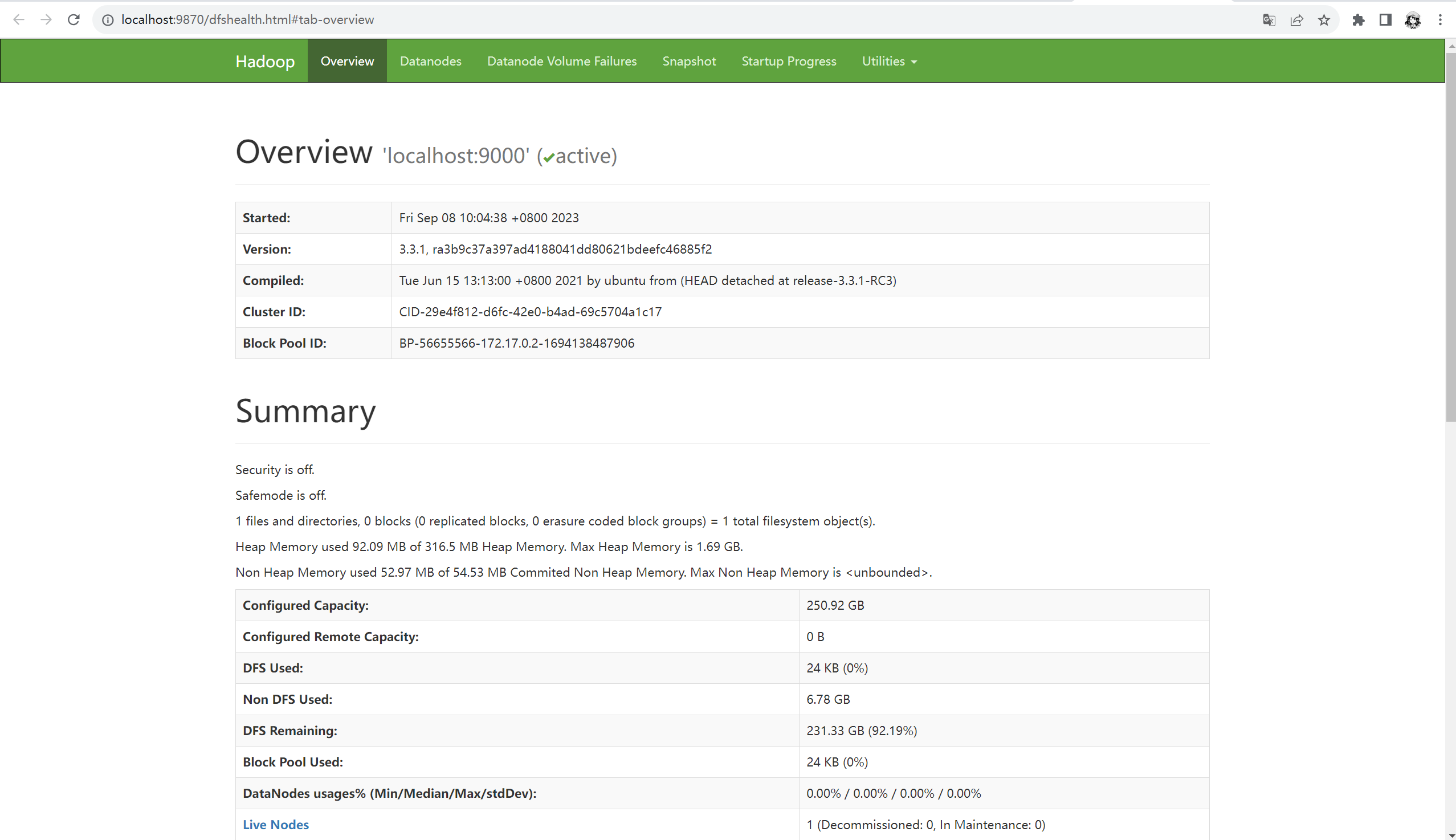
打开浏览器输入http://localhost:9870,成功打开
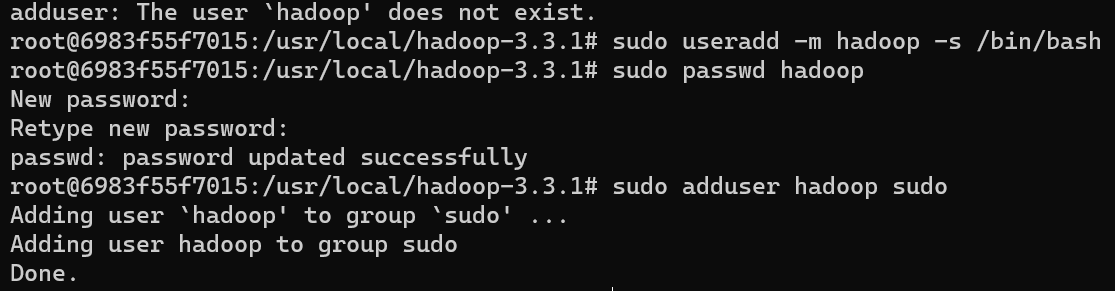
4)创建Hadoop用户组
使用/bin/bash作为shell:
1 | sudo useradd -m hadoop -s /bin/bash |
设置密码:
1 | sudo passwd hadoop |
添加hadoop至管理员权限:
1 | sudo adduser hadoop sudo |
七、配置yarn
搭建前请保证已经搭建好了HDFS的环境,即配置好所上内容。
1)终端输入hostname查看主机名
1 | hostname |
2)打开/etc/hadoop下yarn-site.xml,在configuration标签中加入如下内容,注意主机名要修改为自己的
1 | <property> |
3)打开mapred-site.xml 文件,配置如下(在configuration标签中间加入)
1 | <property> |
4)在主文件夹输入命令启动yarn
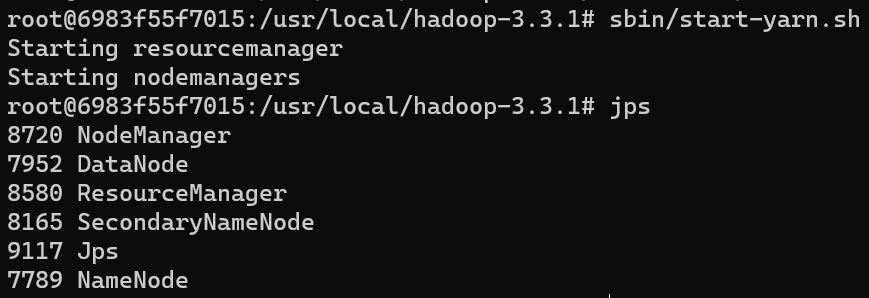
1 | sbin/start-yarn.sh |
jps查看进程多了两个东西
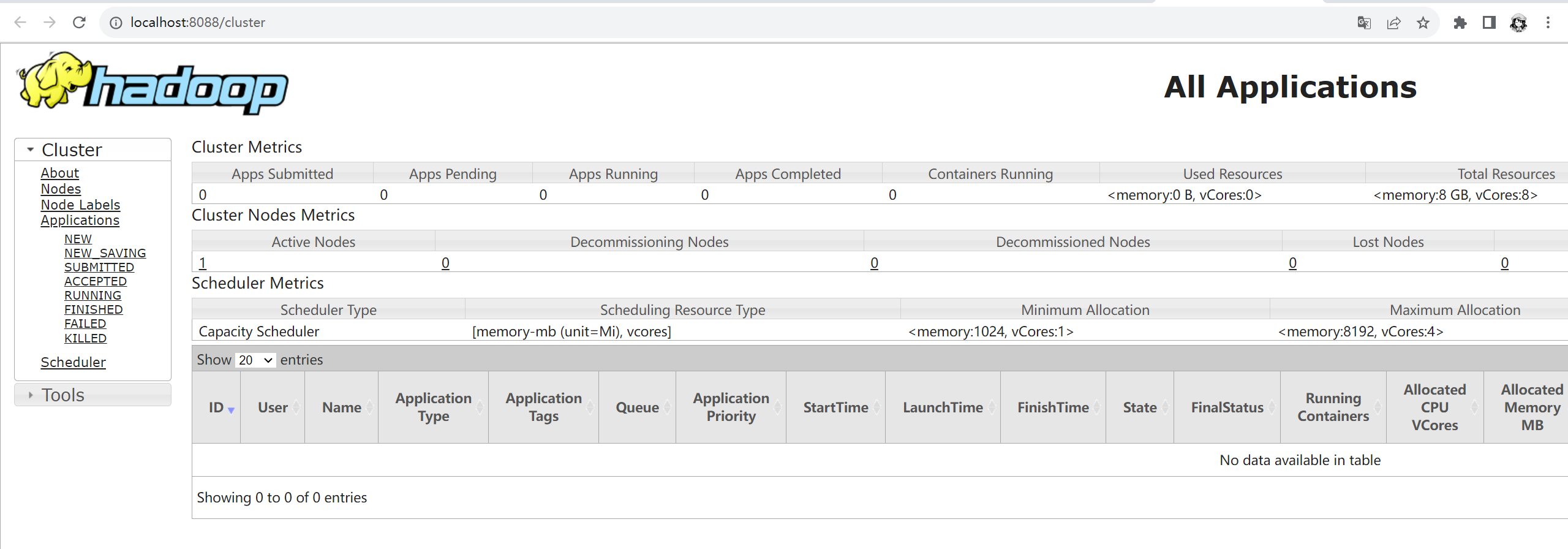
在浏览器输入http://localhost:8088
至此,hadoop全部配置完成
创建镜像
为了后期使用方便,我们可以将容器保存为镜像
1 | docker commit main hadoop_base |
这样我们想要启动一个新的容器时只需要在镜像上启动就行了
1 | docker run -dit -p 9870:9870 -p 8088:8088 main hadoop_base |
参考链接:
https://blog.csdn.net/weixin_58707437/article/details/127931069